Lecture1&2
Q: 在CUDA中,什么是kernels?
A: kernels 类似于 C++ 中 functions,当调用它时,会并行地被不同线程执行。如果有 N 个线程,就被并行地执行 N 次。
Programming Model for CUDA
- Each CUDA kernel
- is executed by a grid
- grid is a 3D array of thread blocks, which are 3D arrays of threads
- Each thread
- executes the same program (kernel) on distinct data address
- has a unique identifier to compute memory addresses and make control decisions
- Single Program Multiple Data (SPMD)
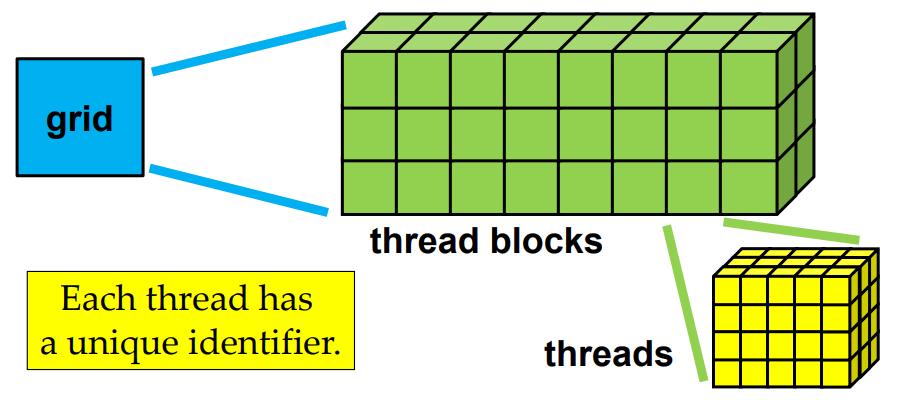
Thread Hierarchy
gridDim
- gridDim gives number of blocks
- Number of blocks in each dimension is
- gridDim.x = 8, gridDim.y = 3, gridDim.z = 2
- Each block has a unique index tuple
- blockIdx.x : [0, griDim.x-1]
- blockIdx.y : [0, griDim.y-1]
- blockIdx.z : [0, griDim.z-1]
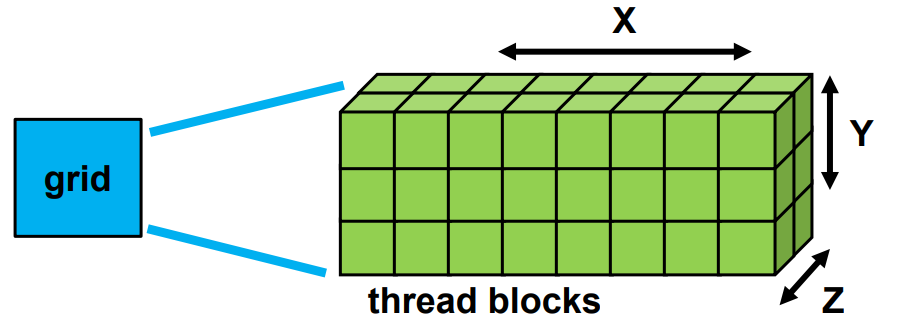
blockDim
- blockDim gives number of threads
- Number of blocks in each dimension is
- blockDim.x = 5, blockDim.y = 4, blockDim.z = 3
- Each thread has a unique index tuple
- threadIdx.x : [0, blockDim.x-1]
- threadIdx.y : [0, blockDim.y-1]
- threadIdx.z : [0, blockDim.z-1]
NOTES
- A thread block may contain up to 1024 threads.
- 坐标系是固定的

每个 threadIdx 在它的 block 中是唯一的,threadIdx 加上 blockIdx 在 grid 中是唯一的。
Example
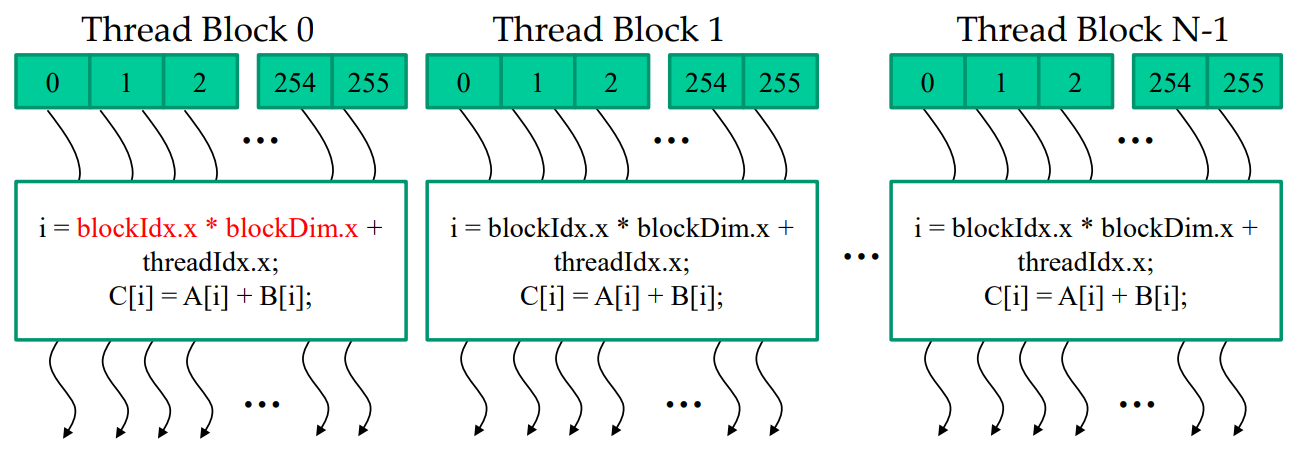 上面 vector add 的例子中 block 和 grid 均是一维.
上面 vector add 的例子中 block 和 grid 均是一维.
__global__ void vecAdd(float* A, float* B, float* C, int n) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < n)
C[i] = A[i] + C[i];
}
int main() {
// omit allocations of A, B, C, n
vecAdd<<<std::ceil(n/256.0), 256>>>(A, B, C, n);
// Or
dim3 DimGrid = (std::ceil(n/256.0), 1, 1);
dim3 DimBlock = (256, 1, 1);
vecAdd<<<DimGrid, DimBlock>>>(A, B, C, n);
}
每个 thread 并行执行 vecAdd kernel,计算数据的 memory address,这里每个 thread 只计算一个 output element.
NOTES
若是想让一个 thread 计算多个 output elements,可以让一个 thread 计算多个 memory addresses,之后我们顺序执行对 output elements 的计算。
例如每个 thread 执行两次加法操作,这样需要的 thread blocks 减少一半。需要两次获取对应的 A 和 B 的 address。
__global__ void vecAdd(float* A, float* B, float* C, int n) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < n)
C[i] = A[i] + C[i];
i = i + blockDim.x;
if (i < n)
C[i] = A[i] + C[i];
}
int main() {
// omit allocations of A, B, C, n
vecAdd<<<std::ceil(n/2 * 256.0), 256>>>(A, B, C, n);
}